
Environment variables (ENV)
This page describes how to use environment variables in Crafting sandbox for your development needs. The outline is as follows:
- Types of environment variable definitions in sandbox
- Use Secret in Environment Variables
- How do environment variables take effect
- Admin guide for environment variables
Types of environment variable definitions in sandbox
Crafting platform supports multiple tiers of environment variables injection/customization in workspaces:
- Built-in environment variables: injected by default for all processes in the workspace;
- Sandbox-level environment variables;
- Workspace-level environment variables;
- User-defined environment for hooks, daemons, jobs in each checkout;
- User-defined environment for interactive shells.
Built-in environment variables
The following environment variables are injected into workspaces by default:
Variable | Value Description | Value Example |
|---|---|---|
| The base URL to access the Crafting Sandbox system. The URL is |
|
| The domain part of |
|
| The suffix for constructing DNS names after |
|
| The name of the current organization. |
|
| The ID of the current organization. | |
| The name of the current Sandbox. |
|
| The ID of the current Sandbox. | |
| The name of the Template that the Sandbox is created from. It's only available when the Sandbox is created from a Template. |
|
| The name of the current workspace. |
|
| The ID of the Sandbox owner, if available. | |
| The email of the Sandbox owner, if available. | |
| The display name of the Sandbox owner, if available. | |
| The Internet facing DNS domain of the Sandbox. Often, it has the format |
|
| The suffix for Internet facing DNS names of endpoints. The complete DNS name of an endpoint can be constructed using |
|
| The job ID, if the sandbox is created for a job | |
| The job execution ID, if the sandbox is created for a job | |
| The sandbox Pool ID if the sandbox is currently in the pool | |
| Service linking environment variables. See Use environment variables for service linking below. |
|
The built-in environment variables can be used by the code running in the sandbox to choose to use specific config for the sandbox environment.
Sandbox-level environment variables
These environment variables are defined in Template as part of Sandbox Definition and apply to all the workspaces in the sandbox, affecting shell, IDE, hooks, and daemons/jobs defined in Repo Manifest. They are defined in the top-level env section in Sandbox Definition:
# These environment variables applies to all workspaces.
env:
- DEV_ENV=development
- APP_URL=https://app${SANDBOX_ENDPOINT_DNS_SUFFIX} # Expansion is supportedWorkspace-level environment variables
Environment variables can be defined in the env section of a workspace in in Sandbox Definition, which only applies to the workspace. For example:
# These environment variables applies to all workspaces.
env:
- DEV_ENV=development
- APP_URL=https://app${SANDBOX_ENDPOINT_DNS_SUFFIX} # Expansion is supported
workspaces:
- name: frontend
# These environment variables applies to the workspace only
env:
- EXTERNAL_URL=${APP_URL}Environment variables for Repo Manifest
Repo Manifest defines hook scripts, daemons, and jobs per checkout. In the manifest, environment variables can be defined to be shared by all hook scripts, daemons, and jobs or for individual commands/scripts. Environment variable expansion is supported in both cases.
Here's an example:
env: # Environment variables shared by all hooks, daemons and jobs.
- EXTERNAL_ENDPOINT_NAME=app
- EXTERNAL_URL=https://${EXTERNAL_ENDPOINT_NAME}${SANDBOX_ENDPOINT_DNS_SUFFIX}
hooks:
build:
cmd: |
./scripts/build.sh
./scripts/seed-db.sh
env:
- 'DB_SERVER_ADDR=${DB_SERVICE_HOST}:${DB_SERVICE_PORT}'
- 'APP_URL=${EXTERNAL_URL}'
daemons:
server:
run:
cmd: './scripts/server.sh --app-url=${EXTERNAL_URL}'
jobs:
post:
run:
cmd: './scripts/post.sh $EXTERNAL_URL'
schedule: "*/10 * * * *"The env section on the top defines the environment variables shared by all the commands defined in the manifest. See Shared Environment for more details. hooks.build.env defines the environment variables used by the build hook only. See Run Schema for more details.
Note: The environment variables defined in the Repo Manifest are ONLY effective for the commands defined in the manifest. I.e., they are not present in interactive shells such as SSH session or Web IDE session. For that reason, we recommend to useWorkspace-level environment variables in most cases if possible.
Environments in Shell Scripts
Environments Undefined in Shell ScriptsAs a common problem, an environment is well-defined when using SSH to access my workspace, but this environment is undefined in my post-checkout, build scripts, neither in the daemon scripts.
Most likely, this is caused by the default .bashrc file in the base snapshot which is built from commonly used Linux distributions (like Ubuntu). The file contains the following at the beginning:
# If not running interactively, don't do anything
case $- in
*i*) ;;
*)
return
;;
esacWhen using SSH, the bash runs in interactive mode (unless given special flags), and thus the whole .bashrc file is loaded as expected. However, most of the automation/background scripts (like post-checkout, build hooks, daemons etc) ran by bash in non-interactive mode, as a result, the content in the .bashrc file is skipped by the a few lines described above. As the installation procedure of many tools are appending environment variables (like PATH) to .bashrc, they are NOT effective in background scripts, but works normally in SSH sessions.
Suggestions
- Explicitly define important environment variables in the Template or Sandbox definition, at sandbox-level, workspace-level or in the Repo Manifest;
- Craft your own
.bashrcfile in the base snapshot/etc/skel/.bashrcor/etc/skel.sandbox/.bashrcto make it consistent between interactive and non-interactive modes.
Use Secret in Environment Variables
The content of a shared secret can be extracted into the value of an environment, with prefixing and suffixing whitespaces trimmed. For example:
env:
- MY_APP_KEY=key:${secret:app-key}The form ${secret:SECRET-NAME} can be used to extract the content of the secret into the value. Only organizational secret can be referenced.
How do environment variables take effect
Merge of environment variables
Environment variables are defined in different places for different scopes, and they are merged to generate the final set of environment variables in the following order:
- Built-in environment variables
- Sandbox-level environment variables
- Workspace-level environment variables
- For hooks, daemons, and jobs in Repo manifest only
- Env defined in top-level
envsection of repo manifest - Env defined per hook/daemon/job
- Env defined in top-level
The expansion is evaluated immediately when an environment variable is appended to the merging process. Given the following example of a Sandbox Definition:
# These environment variables applies to all workspaces.
env:
- DEV_ENV=development
- APP_URL=https://app${SANDBOX_ENDPOINT_DNS_SUFFIX} # Expansion is supported
workspaces:
- name: frontend
# These environment variables applies to the workspace only
env:
- EXTERNAL_URL=${APP_URL}
- APP_URL=https://testThe final environment variables in a shell of the frontend workspace contains (built-in environment variables not listed here):
DEV_ENV=development
EXTERNAL_URL=https://app--mysandbox-org.sandboxes.run
APP_URL=https://testWhen EXTERNAL_URL is appended, expansion is evaluated immediately, and at that time, APP_URL is <https://app--mysandbox-org.sandboxes.run>.
The last APP_URL=<https://test> overrides the existing APP_URL.
Override environment variables at sandbox creation
At sandbox creation time, the creator can further adjust environment variable setting for the sandbox. As shown above, the create can add more ENV definitions to sandbox-level and workspace level.
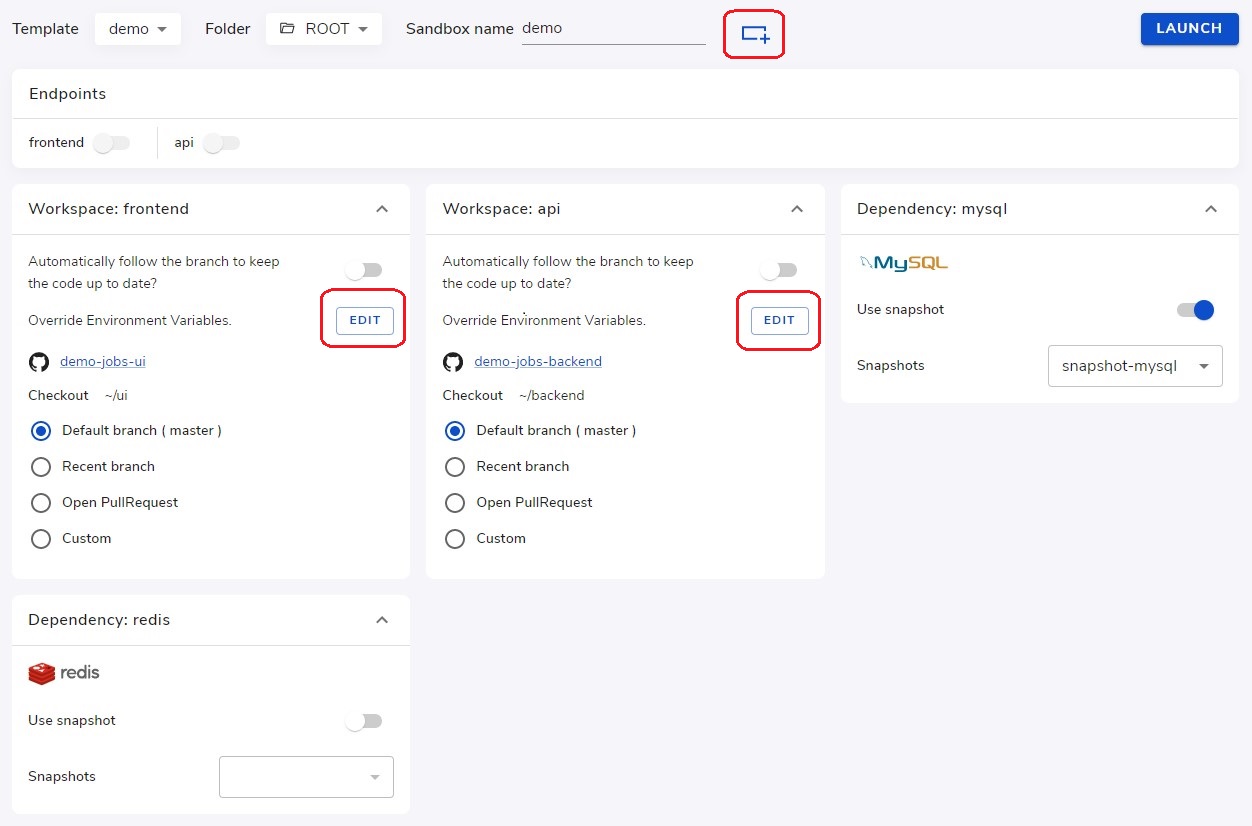
Here, new ENV definitions can be appended at the bottom of existing definitions from the template. The new ENV definitions can expand from the existing definitions, and can re-define the ENV already in the existing definitions.
When changes are applied to the sandbox
The environment variables defined above are effective once the workspace is created in a sandbox. However, there may be further changes on the sandbox after creation (e.g. synchronized from a changed Template). Moreover, the change may cause differences in environment variables (e.g. adding workspaces/dependencies affects service linking environment variables, adding/removing packages affects PATH). The new changes won't be populated to all existing processes, including WebIDE servers and VS Code remote servers if they are running.
New processes after the change will pick up new values. Change of Repo Manifest is only effective the next time a command is executed. The running daemons stay with the old environment. Use cs restart to restart daemons to use the new environment.
Admin guide for environment variables
Following best practices are suggestions to team admins for manage environment variables in their team's development environments. They are advanced topics, some of which require further setup in the Template. See Setup Templates for Dev Environments
Do not quote values in YAMLWhen defining environment in sandbox definition, repo manifest etc. Do not put quotes around the value, otherwise the quotes become part of the value.
Use environment variables for service linking
Service linking (aka service injection) is one of the standard service discovery mechanisms that works by injecting environment variables into the container where the service runs in order to discover and communicate with other services. The environment variable name is constructed using the following rules:
<service-name>_SERVICE_HOSTspecifies the address or hostname of the service.<service-name>_SERVICE_PORTspecifies the port number of the default port of the service (the first exposed port according to Sandbox Definition).<service-name>_SERVICE_PORT_<port-name>: specifies the port number of each exposed port.- Dashes
-in<service-name>and<port-name>are converted to underscores_.
Take the below example Sandbox Definition:
workspaces:
- name: frontend
ports:
- name: http
port: 3000
protocol: HTTP/TCP
- name: backend
ports:
- name: api
port: 8080
protocol: HTTP/TCP
- name: metrics
port: 9090
protocol: HTTP/TCP
dependencies:
- name: db
service_type: mysql
- name: redis
service_type: redisIt will inject the following environment variables in each workspace (both frontend and backend):
FRONTEND_SERVICE_HOST=frontendFRONTEND_SERVICE_PORT=3000FRONTEND_SERVICE_PORT_HTTP=3000BACKEND_SERVICE_HOST=backendBACKEND_SERVICE_PORT=8080BACKEND_SERVICE_PORT_API=8080BACKEND_SERVICE_PORT_METRICS=9090DB_SERVICE_HOST=dbDB_SERVICE_PORT=3306DB_SERVICE_PORT_MYSQL=3306REDIS_SERVICE_HOST=redisREDIS_SERVICE_PORT=6379REDIS_SERVICE_PORT_REDIS=6379
Use Secret to store sensitive information which are used to stored in ENV
To conveniently provide environment overrides with sensitive information, place a simple shell script, assigning environment variables into a secret.
For example, to create a secret db-env that contains a script defining database access credentials:
cat <<EOF | cs secret create --shared db-env -f -
export DB_USERNAME=demouser
export DB_PASSWORD='!@#$%^7890'
EOFAppend the following line to ~/.bashrc to load the environment variables:
. /var/run/sandbox/fs/secrets/shared/db-envAdd .bashrc to ~/.snapshot/includes.txt and create a Home Snapshot using cs snapshot create --home NAME. Then use this Snapshot in the Sandbox Definition for this workspace.
For more information regarding Secret, please see Secrets for storing dev credentials
How to use direnv
direnv is a powerful tool for terminal users. It intercepts the cd command (changing current directory) and updates the current environment variables accordingly if the new cwd (current working directory) or its ancestor contains a .envrc file. Follow the steps below as an example to setup direnv in a workspace:
- Install
direnvto the root file system of the workspace (e.g. in/usr/local/bin, according to the document). - Create a config file
~/.config/direnv/config.tomlwith the following content to trust all.envrcfiles under the user's home directory:
[whitelist]
prefix = [
"/home",
]- Append
eval $(direnv hook bash)into~/.bashrcto activatedirenv. - Add
~/.configand~/.bashrcto~/.snapshot/includes.txtso they will be included in a home snapshot. - Create Base Snapshot using
cs snapshot create NAME. - Create Home Snapshot using
cs snapshot create --home NAME. - Update Template to use these Snapshots for the workspace.
- Submit
.envrcfiles into code base with environment variables.
The next time a new Sandbox is created, inside a workspace, cd into a folder containing checked out code will automatically populate the environment variables defined in the .envrc file.
How to use dotenv package for Node.js
dotenv is a popular package used in many Node.js projects to populate environment variables from a .env file for the current Node.js application. And mostly, the .env file contains sensitive information. It's good practice to save the .env file as a secret, and load it into the project using a post-checkout hook:
- Create a secret from a
.envfile:
cat <<EOF | cs secret create --shared env -f -
API_KEY=a46fg78a90eecd
API_SECRET=ZTdmNTUxMWItMTU1NC00ZDNkLWEzNjctODA3ZjA3MmY1OGJiCg==
EOF- Add to the
post-checkouthook in Repo Manifest:
hooks:
post-checkout:
cmd: |
do something ...
cp -f /var/run/sandbox/fs/secrets/shared/env .env # copy .env from a secretTroubleshooting
Remote Command Execution
This is a very common issue people ran into when running a command remotely using either cs ssh or cs exec and found some environment variables are not set. However, as they are working in an interactive SSH session, a Web Terminal or a VSCode terminal, everything works fine. The issue may also happen when a daemon is defined but failed to run due to missing environment variables.
This is caused by the default ~/.bashrc template introduced in the Ubuntu or Debian images which skips the whole file in bash's non-interactive mode. This file will contain the following at the beginning:
# If not running interactively, don't do anything
case $- in
*i*) ;;
*) return;;
esacAccording to bash's document, commands run using bash -c COMMAND will run in non-interactive mode. Specifically, the following commands will run in non-interactive mode:
cs ssh COMMANDcs exec COMMAND- The command specified in a daemon
For example, when using ruby installed by rbenv or rvm, the environment variables are injected by adding specific lines in ~/.bashrc, as a result, when run commands like: cs ssh ruby myapp.rb or cs exec ruby myapp.rb including in a daemon with command ruby myapp.rb may all fail with something like ruby not found, because the lines inserted into ~/.bashrc is completely ignored in non-interactive bash mode.
On the contrary, when run cs ssh (no following command) or cs exec, it will just invoke bash which will show a prompt and run in interactive mode. As ~/.bashrc is fully loaded, all environment variables are properly set.
Regarding the solutions, there are multiple options:
- Force the interactive mode (only applicable with
cs exec), like:cs exec -u 1000 -W sandbox/workspace -- bash -i -c 'COMMAND'
- If the lines injected in
~/.bashrcis simple, just add the same lines before the command; - If the lines injected in
~/.bashrcis complicated:- Move those lines into a separate file like
~/.env - Replace those lines in
~/.bashrcwith. .env - Add
. .env;before commands to run remotely, likecs exec -- bash -c '. .env; ruby myapp.rb'
- Move those lines into a separate file like
Specifically for cs exec, which runs using the root user as default. If you need to load env from the regular owner user, the flag -u 1000 must be specified.
Updated 9 months ago